Towards an advanced Git course
What Git commands should be included in an “intermediate” or “advanced” Git course? Is there any logical order to teach Git commands that can facilitate the students’ learning? How many commands and/or topics should you teach before introducing, for example, git cherry-pick?.
Can the order in which we teach the Git commands affect how easy is to learn them?
I started thinking about this from my experience teaching and re-designing a Git course. Could it imply more effort on the instructor’s side to introduce git stash than git reset at the end of a class? Is there any kind of pre-requisite knowledge needed to learn these commands?
Identifying pre-requisite knowledge for the topics and/or commands to be taught could be useful for:
Organizing and designing Git classes at different levels;
Creating a pre-selection of material and activities to cover potential gaps in learning. Some students’ questions about Git emerge in courses not focused on Git, but involving intensive use of this tool. For example, project-based courses; and
Exchanging with other instructors, improving the material for subsequent course offerings.
Before we even start thinking about this, let’s explore what is covered in advanced Git courses.
What commands are covered in intermediate/advanced Git courses?
I explored some courses offered online to see if there is some kind of pattern in the commands considered intermediate/advanced. They are listed below:
LinkedIn - Git intermediate techniques - Rebase, cherry-picking, staging, branch management techniques.
Atlassian - Advanced Git tutorials - Merging vs. Rebasing, Resetting, Checking Out, and Reverting, Advanced Git Log, Git Hooks, Refs and the Reflog,
git prune, Git subtree, Git LFS,git gc, Git LFS, Git Bash,git cherry-picking, Git submodules among other topics.Toptal - The advanced Git Guide -
git rebase,git squash,git bisect,git stash,git reset, andgit revert.Udemy - Git: Advanced commands -
git commit --amend,git reflog,git rebase,git config --global alias,git fetch --prune,git reset [both soft and hard resets],git clean,git revert,git cherry-pick,git stash,git tag, Squash and Merge, Rebase.GitKraken - tutorials
- Git Intermediate -
git merge,git stash, Git hooks,git squash, pull requests,git rebase,git cherry-pick - Git Advanced - Solving merge conflicts, Git LFS, Git submodules.
- Git Intermediate -
Even if there are some repeated commands among these courses considered advanced (git rebase, git squash and git cherry-pick are some of them), there are other less obvious options. Is teaching to solve merge conflicts an advanced use of Git? Or should it be introduced alongside teaching pull requests?
Even if reflecting on this was interesting, there is something that we should consider when we want to use this information to affect our teaching plans:
Is teaching Git equal to teaching Git commands?
This question is clearly answered in chapter 5 of Teaching Tech Together (Wilson (2019)):
“Your goal when teaching novices should therefore be to help them construct a mental model so that they have somewhere to put facts. For example, Software Carpentry’s lesson on the Unix shell introduces fifteen commands in three hours. That’s one command every twelve minutes, which seems glacially slow until you realize that the lesson’s real purpose isn’t to teach those fifteen commands: it’s to teach paths, history, tab completion, wildcards, pipes, command-line arguments, and redirection.” -Wilson (2019)
It is not only about the commands. Rather, it is the “units of content”, topics or even narratives that we want to teach, generally listed as the course learning objectives. These topics will define a mental model that is the basis of what we expect the students to be able to reproduce. We can say then, that each mental model will act as an organizer of the flow of Git commands to teach during a class. As an example, if “create a pull request” is a learning objective, we can teach a mental model that includes the commands git switch -c <branch>, git add, git commit, git push and some GitHub user interface options.
A mental model can be defined as follows:
Mental model: A simplified representation of the key elements and relationships of some problem domain that is good enough to support problem-solving. -Wilson (2019)
Dealing with abstraction is probably one of the major obstacles to creating mental models. Being able to become a skilled Git user requires operating with abstraction. Based on my experience, teaching with live coding is not enough. There should be extra effort to support novice students in their creation of a mental model, by way of activities and/or exercises.
When it comes to Git, creating a representation involves linking the Git commands as well as defining the compartments where the commands operate. For example, it is common to find explanations in initial Git courses about what the staging area is in order to understand basic commands such as git add and git commit.
From now on, I will talk about commands and compartments as two different elements of my representations.
A one-size fits-all representation?
Not only could there be more than one mental model needed to explain Git, but they could all have different grades of complexity.
There are many possible representations to teach Git (some of them are shown in fig. 1), and there should be carefully selected in relation to our learning objectives to avoid confusing the students.
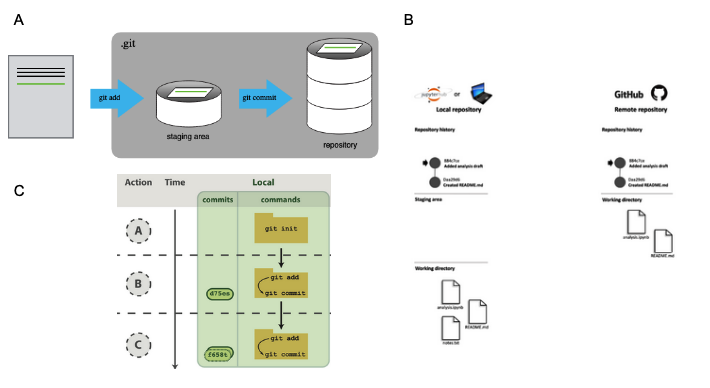
.git folder (Munk et al. 2019) (B) This image shows clearly that the staging area only exists in the local repository. The commits are represented in the local and remote repository, including commit message and hash (Timbers, Campbell, and Lee 2022). The representation in (C) includes time as a variable to explain the Git command workflow (Blischak, Davenport, and Wilson 2016)
To start, I can think in at least two initial mental models that I used in my classes: one to teach the Git basic workflow, that can have different grades of complexity, and a second one, more advanced, to teach branching.
I will supply an example:
Initial mental model: Step 1
compartments: Working directory, staging area and local repository
commands: 1. git add 2. git status 3. git commit 4. git log
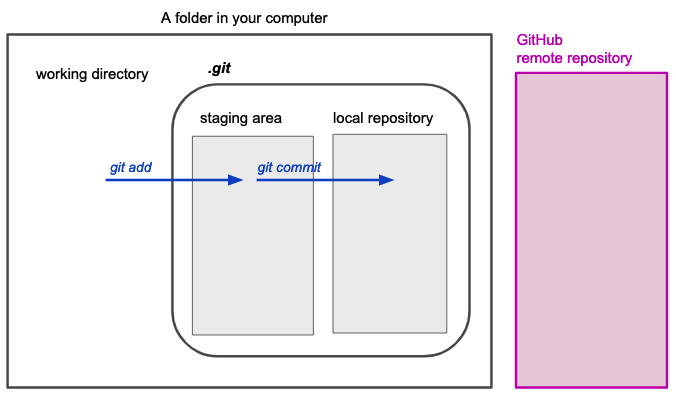
Initial mental model: Step 2
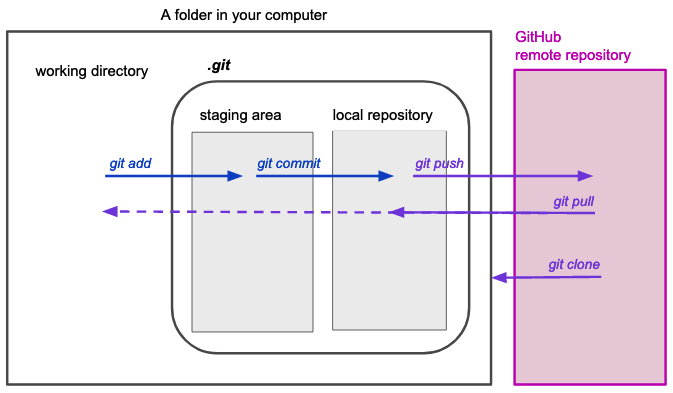
new compartment: remote repository
commands: 5. git clone 6 and 7. git push and git pull
Why?
The working directory and the repository itself and how all these compartments are linked deserves some explanation.
I am considering
git logandgit statuspart of these first basics commands as they are keys to depict what is going on in both areas and help us to depict the model.
Special case:
git pullThe commandgit pulldeserves a spetial section as to fully understand it mix betweengit mergeandgit fetch
Initial mental model: Step 3
new compartment: Stashing area
command: 10. git stash
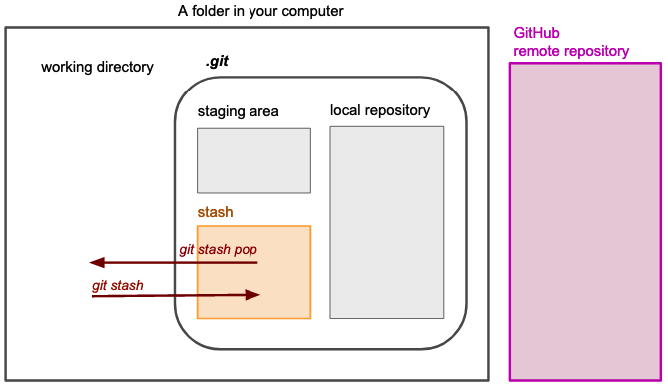
Why?
- Even if we are still working with the same areas or compartments, understanding how these commands work implies adding a new area to the mental model the students have built so far. Not only should the students understand what the commands do, but they must also understand how this new area interacts with the rest of the compartments and where it is located inside the ‘.git’ folder
Tell me your mental model, and I will tell you what command to learn next…
Now, imagine that you are designing a class when you teach the commands 1-10. Then, you decide you want to include the commands git reset --hard and git reset --soft. Where in this sequence of commands would you teach them?
git resetis a command that deletes the project history. What sets it appart from other commands, is the flag--hardand--softare pointing to which compartment the command is operating.git reset --hardwill simply delete the history of the project, butgit reset --softwill dissolve the commit and sent the information contained inside it to the staging area.
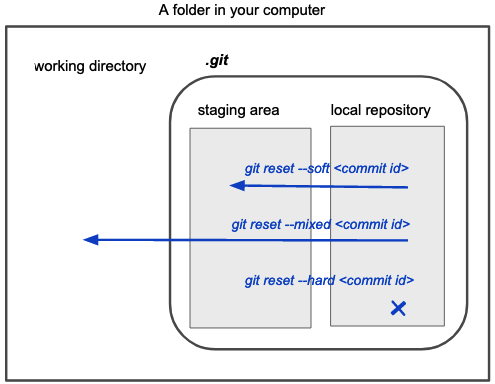
Why?
The students don’t need more than the compartments taught in the initial mental model: step 1 to learn these commands. So, if the learning objectives allow us, these commands could taught after the basic workflow without much explanation. It isn’t necessary to introduce the remote repository to understand what these Git commands do.
This being said, with git reset --hard and git reset --soft we are considering for the first time that flags can significantly alter the action of a command. For students that are learning coding at the same time, this could warrant an extra explanation about how flags work.
Final thoughts:
Educators should define in advance one (or more) Git representations they expect students to achieve by the end of a course. For example, in an initial course there could be one representation proposed for teaching the basic Git workflow and then another one to teach branching.
If an educator wants to add more material to a lecture, they should only incorporate commands and concepts applicable to the mental model(s) required in that course.. There should be a considerable amount of exercises or explanations selected to help the student to move to a new stage of the representation. If there is not enough time or material available for it, it is better to only incorporate commands or exercises that can be solved applying the same representation. For example, adding the command
git restoreto themental model: step 1should not be particularly challenging, as there are not new compartments to teach (git restorecould be considered the reverse ofgit add).The mental models evolve from beginners to advanced users, and can have “intermediate stages”. Also, there could be completely different mental models interwoven in a Git course. If the educators are conscious about the representations they are helping to build, they create / select activities that allow the students to transition to new stages of the same mental model or to a different model.
Towards an advanced Git course
This blog post was born as a side-product of my project “Git Instructor Kit”. My goal is to help instructors that want to improve their pedagogical toolkit by compiling a full set of exercises and materials to support Git courses.
Acknowledgements
I would like to thank the CONICET researcher Juliana Benitez for her comments about this blog-post.